Linuxの標準入出力の概要とRubyの例も交えてまとめてみた
はじめに
多少は実践的にLinux使えるようになりたいと思い書籍「新しいLinuxの教科書」を読み進めています。
本記事では「新しいLinuxの教科書」で学んだ内容と別途気になって調べた内容や知識も含めアウトプットしていきます。
前回の記事の続きとなっております。
標準入力 / 標準出力 / 標準エラー出力
標準入力、標準出力、標準エラー出力は、プログラムの基本的な入出力手段です。
Linuxでは、コマンドが実行されると自動的に標準的な入出力チャネルが開かれます。
チャネルとは日本語では「水路」や「経路」という意味ですが、本書では「データの流れる道」と会釈すると良いと書かれていました。
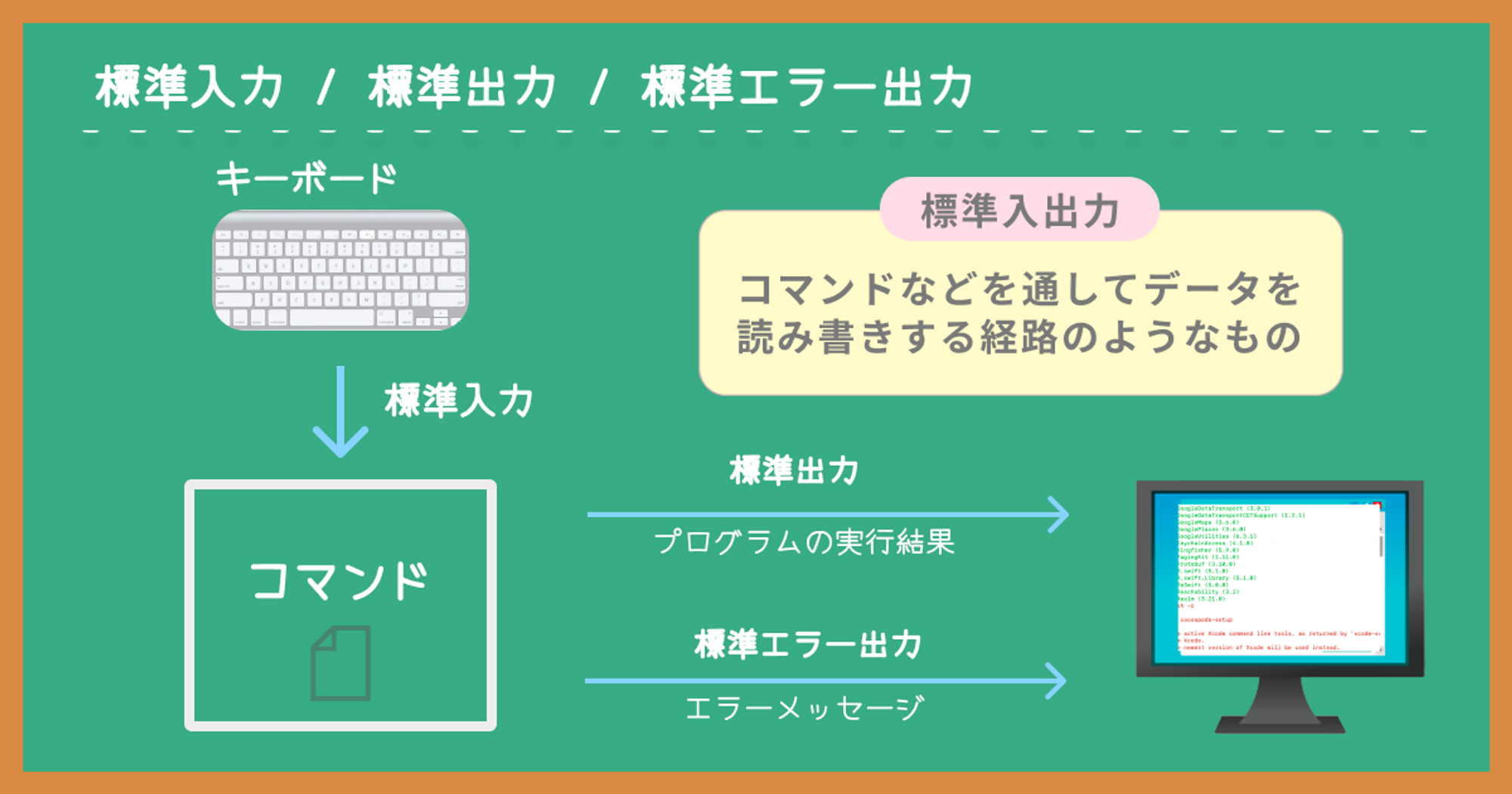
標準入力
プログラムの標準的な入力で、通常はキーボードが使われます。
例えば、getsメソッドを呼び出すと、プログラムは標準入力からのユーザー入力を受け取り、その内容を文字列として返します。
# 標準入力の例 puts "名前を入力してください" name = gets.chomp puts "こんにちは、#{name}さん!"
標準出力
プログラムの標準的な出力で、通常は端末ディスプレイが使われます。
例えば、putsメソッドを呼び出すと、プログラムは標準出力に対して文字列を出力します。この文字列は、ターミナルなどのコンソール上に表示されます。
# 標準出力の例 puts "こんにちは、世界!"
標準エラー出力
プログラムのエラーメッセージを出力するための標準的な出力で、通常の標準出力と同じく端末ディスプレイが使われます。
例えば、ファイルの読み込みに失敗した場合など、プログラムがエラーを出力する必要がある場合に利用されます。
標準出力と同様に、エラーメッセージはターミナルなどのコンソール上に表示されますが、標準出力とは別に出力されます。
# 標準エラー出力の例 $stderr.puts "エラーが発生しました"
要約
これら3つをあわせて標準入出力と呼びます。
また、注意点として各コマンドは、内部で「キーボードから入力されている」、「ディスプレイに出力する」という認識ではなく「標準入力から入力し、標準出力に出力する」という風に考えてください。
リダイレクト
標準入力先を変更する機能をリダイレクトと呼びます。
プログラムが標準入力や標準出力を直接扱う代わりに、リダイレクトを用いることでファイルや別のプロセスなどの別の入出力先に切り替えることができます。
コマンドライン上で「>」や「<」を使って、標準入力や標準出力をファイルにリダイレクトすることができます。
# 実行 (テキストファイルの中身を見る) ❯❯❯ cat output.txt # 結果 (ファイルにoutputという文字があることを確認) output # 実行 (左辺で入力した結果を右辺に標準出力し追記を実行) ❯❯❯ cat test2.txt >> output.txt # 結果 (文字が追記されたことを確認) ❯❯❯ cat output.txt output かきこみ
リダイレクト演算子を表にまとめてみました。
| 演算子 | 詳細 | 使用例 |
|---|---|---|
| > | 左辺のコマンドの標準出力を、右辺のファイルに書き込む。ファイルが存在しない場合は新規作成し、既に存在する場合は上書きする。 | ls > output.txt:lsコマンドの結果をoutput.txtに書き込む。 |
| >> | 左辺のコマンドの標準出力を、右辺のファイルに書き込む。ファイルが存在しない場合は作成する。ファイルが既に存在する場合は末尾に追記する。 | echo "Hello" >> greeting.txt:greeting.txtに"Hello"を追記する |
| < | 左辺のコマンドの標準入力を、右辺のファイルから読み込む。 | sort < input.txt:input.txtの内容をsortコマンドでソートする。 |
| << | 左辺のコマンドの標準入力を、右辺の文字列で置き換える。 | cat << EOF:入力待ち状態になり、EOFで入力を終了するまでの間、入力された文字列をcatコマンドで出力する。 |
実用例: DumpファイルをCLIから投入する
上で解説した演算子を用いてデータベースのバックアップを取ったりコマンドでデータを追加することができます。
データベースは、アプリケーションにとって非常に重要な情報を保持しています。
万が一、データベースが失われた場合、そのデータを失ってしまうことになります。そのため、定期的なバックアップを取ることは非常に重要です。
開発メンバーと共有することもできますし、実際に利用するケースもあると思いますのでまとめておきます。
ローカルに保存したデータをMySQLに投入する
ローカルに落としたデータをデータベースに入れ直すこともあります。
Migrationでなんかやらかしたり、作業上の都合やなんらかの原因でデータベースが上手く動かなくなったりした場合にはバックアップを入れ直すことで簡単に解決できます。
ローカルに保存されているSQLファイルからMySQLデータベースにデータをロードする例です。
# 実行 mysql -u root goenbako_development < /Users/yano/Downloads/goenbako_development_2023-04/13.sql
一応解説します。
mysqlコマンドを使用して、MySQLデータベースに接続します。u rootオプションを使用して、ユーザー名をrootに設定します。goenbako_developmentというデータベースを指定します。<記号を使用して、/Users/yano/Downloads/goenbako_development_2023-03-27.sqlファイルからデータを読み込みます。
この例で使用されたコマンド<は、/Users/yano/Downloads/goenbako_development_2023**-04/13**.sql**というファイルを標準入力としてmysql
コマンドに渡しています。mysql**コマンドは、データベース接続を行っており、受け取った標準入力をデータベースに取り込む。
このように、リダイレクトを使用することで、標準入力や標準出力をファイルと組み合わせることができます。
これにより、ローカルのDumpファイルをデータベースにぶち込むことができました。
MySQLのデータをローカルに落とす
MySQLのデータをローカルにダウンロードする方法はいくつかありますが、ここではmysqldumpコマンドを使った方法を紹介します。
以下のようにコマンドを入力すると、MySQLサーバー上のデータをダンプし、ローカルのファイルに保存することができます。
mysqldump -u [ユーザー名] -p [データベース名] > [保存先ファイル名] # 具体例 mysqldump -u root -p goenbako_development > goenbako_dump.sql
これによりgoenbako_dump.sqlという名前で開発環境のバックアップを取ることができました。
myaqldumpコマンドではユーザー情報をオプションで正しく記述して存在するデータベース名を記述していることに注意してください。
パイプライン
Linuxコマンドラインで2つ以上のコマンドをつないで、前のコマンドの出力を次のコマンドの入力として受け渡す方法のことを指します。
複数のコマンドを組み合わせて、複雑な処理を効率的に行うことができます。
パイプラインの活用方法
あるコマンドの出力を次のコマンドの入力に渡したり、あるコマンドの結果を別のファイルに保存するなどができたり、複数のコマンドをパイプラインでつなげて、一連の処理を自動化することもできます。
ls -l | grep "txt" | sort > output.txt
上記のコマンドは、カレントディレクトリにあるファイルの一覧をリスト表示し、"txt"という文字列を含む行を抽出し、ソートした結果をoutput.txtというファイルに保存します。
各コマンドの出力を次のコマンドの入力に渡し、パイプラインを通じて処理を連携させていることがわかります。
パイプラインはアレに似ている
パイプラインはRuby on Railsにおけるメソッドチェーンによく似ています。
Ruby on Railsで複雑な処理を行う際に、メソッドチェーンを使って処理を連携させることがありますが、パイプラインも同様に、複数のコマンドをつないで処理を自動化することができます。
こういった便利な機能も使いこなしていきたいですね。。
続く…
コメント
本記事の内容は以上になります!
書籍の続きのアウトプットも随時更新したいと思います。
プログラミングスクールのご紹介 (卒業生より)**
お世話になったプログラミングスクールであるRUNTEQです♪
こちらのリンクを経由すると1万円引きになります。

RUNTEQを通じて開発学習の末、受託開発企業をご紹介いただき、現在も双方とご縁があります。
もし、興味がありましたらお気軽にコメントか、TwitterのDMでお声掛けください。